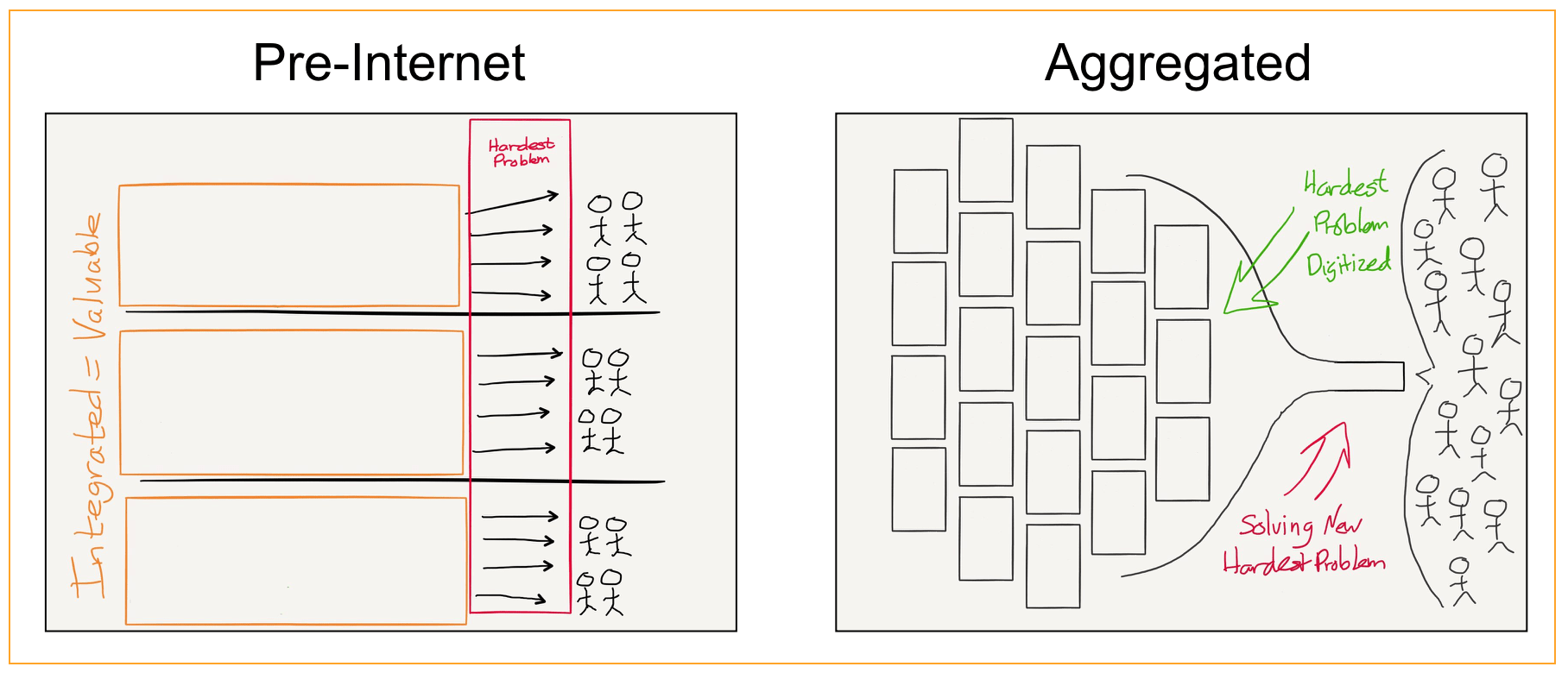
Apple’s increasingly fraught adventures with European regulators is a bit of a morality tale, that goes something like this:
The erstwhile underdog, arguably kept alive by its biggest rival to maintain a figment of competition in the PC market, rides unexpected success in music players to create the iPhone, the device that changed the world while making Apple one of the richest companies in history. Apple, though, seemingly unaware of its relative change in status and power, holds to its pattern — decried in that also-ran PC-era as the cause of their struggles — of total control, not just of the operating system its devices run, but also of 3rd-party applications that helped make the iPhone a behemoth. Ultimately, because of its refusal to compromise, regulators stepped in to force open the iPhone platform, endangering Apple’s core differentiation — the integration of hardware and software — along the way. If only Apple could have seen how the world — and its place in it! — had changed.
This morality tale is one I have chronicled, warned about, and perhaps even helped author over the last decade; like many morality tales, it is mostly true, but also like many morality tales, reality is a bit more nuanced, and filled with alternative morality tales that argue for different conclusions.
Europe’s Data Obsession
During the recent Stratechery break I was in Europe, and, as usual, was pretty annoyed by the terrible Internet experience endemic to the continent: every website has a bunch of regulatory-required pop-ups asking for permission to simply operate as normal websites, which means collecting the data necessary to provide whatever experience you are trying to access. This obviously isn’t a new complaint — I feel the same annoyance every time I visit.
What was different this time is that, for the first time in a while, I was traveling as a tourist with my family, and thus visiting things like museums, making restaurant reservations, etc.; what stood out to me was just how much information all of these entities wanted: seemingly every entity required me to make an account, share my mailing address, often my passport information, etc., just to buy a ticket or secure a table. It felt bizarrely old-fashioned, as if services like OpenTable or Resy didn’t exist, or even niceties like “Sign In With Google”; what exactly is a museum or individual restaurant going to do with so much of my personal information — I just want to see a famous painting or grab a meal!
Your first thought — and mine as well — might be that this is why all of those pop-ups exist: random entities are asking for a lot of my personal data, and I ought to have control of that. I certainly agree with the sentiment — if I lived in Europe and were assaulted with data requests from random entities with such frequency, I would feel similarly motivated — but obviously the implementation is completely broken: hardly anyone, no matter how disciplined about their data, has the time and motivation to read through every privacy policy or data declaration and jump through the hoops necessary to buy a ticket or reserve a table while figuring out the precise set of options necessary to do so without losing control of said data; you just hit “Accept” and buy the damn ticket.
My second thought — and this is certainly influenced by my more business-oriented trips to the continent — is that Europeans sure are obsessed with data generally. On another trip, I was in a forum about AI and was struck by the extent to which European business-people themselves were focused on data to the point where it seemed likely some number of their companies would miss out on potential productivity gains for fear of losing control of what they viewed as some sort of gold mine; the reality is that data is not the new oil: yes, it is valuable at scale and when processed in a data factory, but the entities capable of building such factories are on the scale of a Meta or a Google, not a museum or a restaurant or even a regional bank. I don’t think that AI has changed this equation: the goal of a business ought to be to leverage its data to deliver better business outcomes — which AI should make easier — not obsessively collect and hoard data as if it is a differentiator in its own right.
The third takeaway, though, is the most profound: the Internet experience in America is better because the market was allowed to work. Instead of a regulator mandating sites show pop-ups to provide some sort of false assurance about excess data collection, the vast majority of sites have long since figured out that (1) most of the data they might collect isn’t really that usable, particularly in light of the security risks in holding it, and (2) using third-party services is better both for the customer and themselves. Do you want a reservation? Just click a button or two, using the same service you use everywhere else; want to buy tickets? Just have a credit card, or even better, Apple Pay or Google Wallet.
Moreover, this realization extends to the data obsessive’s bugaboo, advertising. Yes, Internet advertising was a data disaster 15 years ago (i.e. the era where the European Internet seems stuck); the entities that did more than anyone to clean the situation up were in fact Meta and Google: sites and apps realized they could get better business results and reduce risk by essentially outsourcing all data collection and targeting to Meta and Google and completely cut out the ecosystem of data brokers and unaccountable middlemen that defined the first 15 years of the Internet.
Google Shopping
It would be fine — annoying, to be sure, but ultimately fine — if this were where the story ends: the E.U. identifies an issue (excessive data collection) and reaches for a regulatory solution, locking in a terrible status quo, while the U.S.’s more market-oriented approach results in a better experience for users and better business outcomes for businesses. The E.U. is gonna E.U., amirite? After all, this is the regulatory body that somehow thought a browser choice screen would fundamentally alter the balance of power in technology (and to the extent that that old Microsoft decree did, it was to aid Google in locking in Chrome’s dominance).
The first hints that there may be more nefarious motivations to E.U regulation, though, came in a 2017 European Commission decision about Google Shopping, which I wrote about in Ends, Means, and Antitrust. The title referenced the high level takeaway that while I understood the motivation and arguable necessity of regulating Aggregators (the ends), getting the details right mattered as well (the means), and I thought that case fell short for three reasons:
- First, the Google Shopping decision assumed that Google ought never improve the user experience of Google search. Specifically, just because a search for a specific item once returned a shopping comparison site, it was hardly a crime that search improved such that it surfaced the specific item instead of a middleman. I argued that this was bad for users.
- Second, the Google Shopping decision took an artificially narrow view of competition: those random shopping comparison sites that effectively arbitraged insufficiently precise search results in the 1990s were not the sort of competitors that actually delivered the market outcomes that regulation should try to enable; Google’s real competitor in shopping was Amazon and other similarly integrated retailers who were taking users away from search entirely.
- Third, and most problematically, the Google Shopping product in question was actually an advertising unit: the European Commission was getting into the business of dictating how companies could or could not make money.
I wrote in that Article:
You can certainly argue that the tiny “Sponsored” label is bordering on dishonesty, but the fact remains that Google is being explicit about the fact that Google Shopping is a glorified ad unit. Does the European Commission honestly have a problem with that? The entire point of search advertising is to have the opportunity to put a result that might not otherwise rank in front of a user who has demonstrated intent.
The implications of saying this is monopolistic behavior goes to the very heart of Google’s business model: should Google not be allowed to sell advertising against search results for fear that it is ruining competition? Take travel sites: why shouldn’t Priceline sue Google for featuring ads for hotel booking sites above its own results? Why should Google be able to make any money at all?
This is the aspect of the European Commission’s decision that I have the biggest problem with. I agree that Google has a monopoly in search, but as the Commission itself notes that is not a crime; the reality of this ruling, though, is that making any money off that monopoly apparently is. And, by extension, those that blindly support this decision are agreeing that products that succeed by being better for users ought not be able to make money.
Again, there is plenty of room to disagree about what regulations are and are not appropriate, or debate what is the best way to spur competition; the reason I reacted so negatively to this decision, though, was because this specific point struck me as being fundamentally anti-free market: Google was obligated to deliver a search experience on the European Commission’s terms or else. It was a bit of a subtle point, to be sure — the stronger argument was about the validity of product evolution in a way that makes for a better user experience — but recent events suggest I was right to be concerned.
Apple and the Core Technology Fee
Every year June provides a flurry of antitrust news — I guess I am not the only one that goes on vacation in July — and this year was no exception. The most unsurprising was about Apple; from a European Commission press release:
Today, the European Commission has informed Apple of its preliminary view that its App Store rules are in breach of the Digital Markets Act (DMA), as they prevent app developers from freely steering consumers to alternative channels for offers and content. In addition, the Commission opened a new non-compliance procedure against Apple over concerns that its new contractual requirements for third-party app developers and app stores, including Apple’s new “Core Technology Fee”, fall short of ensuring effective compliance with Apple’s obligations under the DMA.
The first item, about Apple’s anti-steering provisions, fits perfectly into the morality tale I opened this Article with. Apple didn’t just create the iPhone, they also created the App Store, which, after the malware and virus muddled mess of the 2000s, rebuilt user confidence and willingness to download 3rd-party apps. This was a massive boon to developers, and shouldn’t be forgotten; more broadly, the App Store specifically and Apple’s iOS security model generally really do address real threats that can not only hurt users but, by extension, chill the market for 3rd-party developers.
At the same time, the implications of the App Store model and iOS’s locked-down nature mean that Apple’s power over the app ecosystem is absolute; this not only means that the company can extract whatever fees it likes from developers, it also hinders the development of apps and especially business models that don’t slot in to Apple’s rules. I think it would have been prudent of the company to provide more of a release valve than web apps on Safari: I have long advocated that the company allow non-gaming apps to have webviews that provide alternative payment options of the developers’ choice; Apple instead went the other way, arguing ever more strenuously that developers can’t even talk about or link to their own websites if that website provided alternative payment methods, and to the extent the company gave ground, it was in the most begrudging and clunky way possible.
These anti-steering rules are the first part of the European Commission’s case, and while I might quibble with some of the particulars, I mostly blame Apple for not self-regulating in this regard. Note, though, that the anti-steering case isn’t just about allowing links or pricing information; this is the third charge:
Whilst Apple can receive a fee for facilitating via the AppStore [sic] the initial acquisition of a new customer by developers, the fees charged by Apple go beyond what is strictly necessary for such remuneration. For example, Apple charges developers a fee for every purchase of digital goods or services a user makes within seven days after a link-out from the app.
As I explained in an Update last month, the charges the European Commission seems to be referring to are Apple’s new Core Technology Fee for apps delivered outside of the App Store, a capability which is required by the DMA. Apple’s longstanding argument is that the fees it charges in the App Store are — beyond the 3% that goes to payment providers — compensation for the intellectual property leveraged by developers to make apps; if it can’t collect those fees via a commission on purchases then the company plans to charge developers €0.50 per app install per year.
Now this is where the discussion gets a bit messy and uncomfortable. On one hand, I think that Apple’s policies — and, more irritatingly, its rhetoric — comes across as arrogant and unfairly dismissive of the massive contribution that 3rd-party developers have made to the iPhone in particular; there’s a reason why Apple’s early iPhone marketing emphasized that There’s an App for That:
At the same time, to quote an Update I wrote about the Core Technology Fee:
There simply is no question that iOS is Apple’s intellectual property, and if they wish to charge for it, they can: for it to be otherwise would require taking their property and basically nationalizing it (while, I assume, demanding they continue to take care of it). It is frustrating that Apple has insisted on driving us to this fundamental reality, but reality it is, and the DMA isn’t going to change that.
It sure seems that this is the exact scenario that the European Commission is headed towards: demanding that Apple make its intellectual property available to third party developers on an ongoing basis without charge; again, while I think that Apple should probably do that anyways, particularly for apps that eschew the App Store entirely, I am fundamentally opposed to compelling a company to provide its services for free.
Meta and Pay or Consent
An even better example of the European Commission’s apparent dismissal of private property rights is Meta; from the Financial Times:
The European Commission, the EU’s executive body, is exercising new powers granted by the Digital Markets Act — legislation aimed at improving consumer choice and opening up markets for European start-ups to flourish. The tech giants had to comply from March this year. In preliminary findings issued on Monday, Brussels regulators said they were worried about Meta’s “pay or consent” model. Facebook and Instagram users can currently opt to use the social networks for free while consenting to data collection, or pay not to have their data shared.
The regulators said that the choice presented by Meta’s model risks giving consumers a false alternative, with the financial barrier potentially forcing them to consent to their personal data being tracked for advertising purposes.
From the European Commission’s press release:
The Commission takes the preliminary view that Meta’s “pay or consent” advertising model is not compliant with the DMA as it does not meet the necessary requirements set out under Article 5(2). In particular, Meta’s model:
- Does not allow users to opt for a service that uses less of their personal data but is otherwise equivalent to the “personalised ads” based service.
- Does not allow users to exercise their right to freely consent to the combination of their personal data.
To ensure compliance with the DMA, users who do not consent should still get access to an equivalent service which uses less of their personal data, in this case for the personalisation of advertising.
Here is the problem with this characterization: there is no universe where a non-personalized version of Meta’s products are “equivalent” to a personalized version from a business perspective. Personalized ads are both far more valuable to advertisers, who only want to advertise to potential customers, not the entire Meta user base, and also a better experience for users, who get more relevant ads instead of random nonsense that isn’t pertinent to them. Indeed, personalized ads are so valuable that Eric Seufert has estimated that charging a subscription in lieu of personalized ads would cost Meta 60% of its E.U. revenue; being forced to offer completely un-personalized ads would be far more injurious.
Clearly, though, the European Commission doesn’t care about Meta or its rights to offer its products on terms it chooses: demanding a specific business model that is far less profitable (and again, a worse user experience!) is once again a de facto nationalization (continentalization?) of private property. And, as a variation on an earlier point, while I don’t agree with the demonization of personalized ads, I do recognize the European Union’s prerogative and authority to insist that Meta offer an alternative; what is problematic here is seeking to ban the fairest alternative — direct payment by consumers — and thus effectively taking Meta’s property.
Nvidia and CUDA Integration
The final example is Nvidia; from Reuters:
Nvidia is set to be charged by the French antitrust regulator for allegedly anti-competitive practices, people with direct knowledge of the matter said, making it the first enforcer to act against the computer chip maker. The French so-called statement of objections or charge sheet would follow dawn raids in the graphics cards sector in September last year, which sources said targeted Nvidia. The raids were the result of a broader inquiry into cloud computing.
The world’s largest maker of chips used both for artificial intelligence and for computer graphics has seen demand for its chips jump following the release of the generative AI application ChatGPT, triggering regulatory scrutiny on both sides of the Atlantic. The French authority, which publishes some but not all its statements of objections to companies, and Nvidia declined comment. The company in a regulatory filing last year said regulators in the European Union, China and France had asked for information on its graphic cards. The European Commission is unlikely to expand its preliminary review for now, since the French authority is looking into Nvidia, other people with direct knowledge of the matter said.
The French watchdog in a report issued last Friday on competition in generative AI cited the risk of abuse by chip providers. It voiced concerns regarding the sector’s dependence on Nvidia’s CUDA chip programming software, the only system that is 100% compatible with the GPUs that have become essential for accelerated computing. It also cited unease about Nvidia’s recent investments in AI-focused cloud service providers such as CoreWeave. Companies risk fines of as much as 10% of their global annual turnover for breaching French antitrust rules, although they can also provide concessions to stave off penalties.
I have been writing for years about Nvidia’s integrated strategy, which entails spending huge amounts of resources on the freely available CUDA software ecosystem that only runs on Nvidia chips; it is an investment that is paying off in a major way today as CUDA is the standard for creating AI applications, which provides a major moat for Nvidia’s chips (which, I would note, is counter-intuitively less meaningful even as Nvidia has dramatically risen in value). The existence of this moat — and the correspondingly high prices that Nvidia can charge — is a feature, not a bug: the chipmaker spent years and years grinding away on GPU-accelerated computing (and were frequently punished by the market), and the fact the company is profiting so handsomely from an AI revolution it made possible is exactly the sort of reward anyone interested in innovation should be happy to see.
Once again, though, European regulators don’t seem to care about incentivizing innovation, and are walking down a path that seems likely to lead to de facto continentalization of private property: the logical penalty for Nvidia’s crime of investing in CUDA could very well be the forced separation of CUDA from Nvidia chips, which is to say simply taking away Nvidia’s property; the more “moderate” punishment could be ten percent of Nvidia’s worldwide revenue, despite the fact that France — and almost certainly the E.U. as a whole — provide nowhere close to ten percent of Nvidia’s revenue.
The Worldwide Regulator
That ten percent of worldwide revenue number may sound familiar: that is the same punishment allowed under the DMA, and it’s worth examining in its own right. Specifically, it’s bizarrely high: while Nvidia doesn’t break out revenue by geography, Meta has said that ten percent of its revenue comes from the E.U; for Apple it’s only 7 percent. In other words, the European Union is threatening to fine these U.S. tech giants more money than they make in the E.U. market in a year!
The first thing to note is that the very existence of these threats should be considered outrageous by the U.S. government: another international entity is threatening to not just regulate U.S. companies within their borders (reasonable!), but to actually take revenue earned elsewhere in the world. It is very disappointing that the current administration is not only not standing up for U.S. companies, but actually appears to view the European Commission as their ally.
Second, just as Apple seems to have started to believe its rhetoric about how developers need Apple, instead of acknowledging that it needs developers as well, the European Commission seems to have bought into its spin that it is the world’s tech regulator; the fact everyone encounters cookie permission banners is even evidence that is the case!
The truth is that the E.U.’s assumed power come from the same dynamics that make U.S. tech companies so dominant. The fundamental structure of technology is that it is astronomically expensive to both develop and maintain, but those costs are more akin to capital costs like building a ship or factory; the marginal cost of serving users is zero (i.e. it costs a lot of money to serve users in the aggregate, but every additional user is zero marginal cost). If follows, then, that there is almost always benefit in figuring out how to serve more users, even if those users come with lower revenue opportunities.
A useful analogy is to the pharmaceutical industry; Tyler Cowen wrote in a provocative post on Marginal Revolution entitled What is the gravest outright mistake out there?:
I am not referring to disagreements, I mean outright mistakes held by smart, intelligent people. Let me turn over the microphone to Ariel Pakes, who may someday win a Nobel Prize:
Our calculations indicate that currently proposed U.S. policies to reduce pharmaceutical prices, though particularly beneficial for low-income and elderly populations, could dramatically reduce firms’ investment in highly welfare-improving R&D. The U.S. subsidizes the worldwide pharmaceutical market. One reason is U.S. prices are higher than elsewhere.
That is from his new NBER working paper. That is supply-side progressivism at work, but shorn of the anti-corporate mood affiliation.
I do not believe we should cancel those who want to regulate down prices on pharmaceuticals, even though likely they will kill millions over time, at least to the extent they succeed. (Supply is elastic!) But if we can like them, tolerate them, indeed welcome them into the intellectual community, we should be nice to others as well. Because the faults of the others probably are less bad than those who wish to regulate down the prices of U.S. pharmaceuticals.
Cowen’s point is that while many countries aggressively regulate the price of pharmaceuticals, you ultimately need a profit motive to invest in the massive up-front cost in developing new drugs; that profit comes from the U.S. market. The reason this all works is that the actual production of drugs is similar to technology: once the drug is approved every marginal pill is effectively zero marginal cost; this means that it is worth selling drugs at highly regulated prices, but you still need a reason to develop new drugs as well.
So it is with technology; to take the Meta example above, the company may very well be brought to heel with regards to offering a non-personalized-ads business model: Facebook and Instagram and WhatsApp are already developed, operations teams already exist, data centers are already built, so maybe a fraction of potential revenue will be worth continuing to offer those services in the E.U. Moreover, there is the matter of network effects: should Meta leave the E.U. it will make its services worse for non-E.U. users by reducing the size of the network on its services.
This is the point, though: the E.U.’s worldwide regulatory power is ultimately derived from the structure of technology, and structures can change. This is where that ten-percent-of-worldwide-revenue figure looms large: it fundamentally changes the calculus in terms of costs. Fines from a regional regulator are not the equivalent of engineering and server costs that you’re already paying so you might as well capture pennies of extra revenue from said region; they are are directly related to revenue from that region. In other words, they are more like marginal costs: the marginal cost of serving the E.U. is the expected value of the chances you will get fined more than you earned in any given year, and for big tech that price is going up.
That’s not the only cost that is going up for Apple in particular: part of the implication of the “Core Technology Fee” model is that Apple has put forth a tremendous amount of engineering effort to accomodate its platform to the DMA specifically. Or, to put it another way, Apple has already forked iOS: there is one version for the E.U., and one version for the rest of the world. This too dramatically changes the calculus: yes, every E.U. user comes in at zero marginal cost, but not the E.U. as a whole: Apple isn’t just paying the expected value of future fines, but actual real costs in terms of engineering time and overall complexity.
In short, the E.U. either has or is about to cross a critical line in terms of overplaying its hand: yes, most of tech may have been annoyed by their regulations, but the economic value of having one code base for the entire world meant that everyone put up with it (including users outside of the E.U.); once that code base splits, though — as it recently did for Apple — the calculations of whether or not to even serve E.U. users becomes that much closer; dramatically increasing potential fines far beyond what the region is worth only exacerbates the issue.
E.U. Losses
I don’t, for the record, think that either Meta or Apple or any of the other big tech companies — with the exception of Nvidia above — are going to leave Europe. What will happen more often, though, are things like this; from Bloomberg:
Apple Inc. is withholding a raft of new technologies from hundreds of millions of consumers in the European Union, citing concerns posed by the bloc’s regulatory attempts to rein in Big Tech. The company announced Friday that it would block the release of Apple Intelligence, iPhone Mirroring and SharePlay Screen Sharing from users in the EU this year, because the Digital Markets Act allegedly forces it to downgrade the security of its products and services.
“We are concerned that the interoperability requirements of the DMA could force us to compromise the integrity of our products in ways that risk user privacy and data security,” Apple said in a statement.
The EU’s DMA forces dominant technology platforms to abide by a long list of do’s and don’ts. Tech services are prohibited from favoring their own offerings over those of rivals. They’re barred from combining personal data across their different services; blocked from using information they collect from third-party merchants to compete against them; and have to allow users to download apps from rival platforms. As part of the rules, the EU has designated six of the biggest tech companies as “gatekeepers” — powerful platforms that require stricter scrutiny. In addition to Apple, that list includes Microsoft Corp., Google parent Alphabet Inc. and Facebook owner Meta Platforms Inc.
I explained in this Daily Update why this move from Apple was entirely rational, including specific provisions in the DMA that seem to prohibit the features Apple is withholding, in some cases due to interoperability requirements (does iPhone screen-sharing have to work with Windows?), and in others due to restrictions on data sharing (the DMA forbids sharing any user data held by the core platform with a new service built by the core platform); in truth, though, I don’t think Apple needs a good reason: given the calculations above it seems foolish to make any additional investments in E.U.-specific code bases.
European Commission Vice-President Margrethe Vestager was not happy, saying at Forum Europa:
I find that very interesting that they say we will now deploy AI where we’re not obliged to enable competition. I think that is that is the most sort of stunning open declaration that they know 100% that this is another way of disabling competition where they have a stronghold already.
This makes absolutely no sense: Apple not deploying AI in fact opens them up to competition, because their phones will be less fully featured than they might be otherwise! Vestager should be taking a victory lap, if her position made a shred of sense. In fact, though, she is playing the thieving fool like other Europeans before her; from 2014’s Economic Power in the Age of Abundance:
At first, or second, or even third glance, it’s hard to not shake your head at European publishers’ dysfunctional relationship with Google. Just this week a group of German publishers started legal action against the search giant, demanding 11 percent of all revenue stemming from pages that include listings from their sites. From Danny Sullivan’s excellent Search Engine Land:
German news publishers are picking up where the Belgians left off, a now not-so-proud tradition of suing Google for being included in its listings rather than choosing to opt-out. This time, the publishers want an 11% cut of Google’s revenue related to them being listed.
As Sullivan notes, Google offers clear guidelines for publisher’s who do not want to be listed, or simply do not want content cached. The problem, though, as a group of Belgian newspapers found out, is that not being in Google means a dramatic drop in traffic:
Back in 2006, Belgian news publishers sued Google over their inclusion in the Google News, demanding that Google remove them. They never had to sue; there were mechanisms in place where they could opt-out.
After winning the initial suit, Google dropped them as demanded. Then the publications, watching their traffic drop dramatically, scrambled to get back in. When they returned, they made use of the exact opt-out mechanisms (mainly just to block page caching) that were in place before their suit, which they could have used at any time.
In the case of the Belgian publishers in particular, it was difficult to understand what they were trying to accomplish. After all, isn’t the goal more page views (it certainly was in the end!)? The German publishers in this case are being a little more creative: like the Belgians before them they are alleging that Google benefits from their content, but instead of risking their traffic by leaving Google, they’re instead demanding Google give them a cut of the revenue they feel they deserve.
Vestager’s comments about Apple Intelligence are foolish like the Belgian publishers: she is mad that Apple isn’t giving her what she claims to want, which is a weaker Apple more susceptible to competition; expect this to be the case for lots of new features going forward. More importantly, expect this to be the case for lots of new companies: Apple and Meta will probably stay in the E.U. because they’re already there; it seems increasingly foolish for newer companies to ever even bother entering. That, more than anything, is why Apple and Meta and the other big tech companies won’t face competition even as they are forced to weaken their product offerings.
It is the cases above, though, that are thieving like the German publishers: it is one thing to regulate a market; it is another to straight up take a product or service on your terms, enabled by a company’s loyalty to its existing userbase. I might disagree with a lot of E.U. regulations, but I respect them and their right to make them; dictating business models or forcing a company to provide services for free, though, crosses the line from regulation to theft.
The E.U. Morality Tale
And so we arrive at another morality tale, this time about the E.U. Thierry Breten, the European Commissioner for Internal Market, tweeted late last year after the E.U. passed the AI Act:
Historic!
The EU becomes the very first continent to set clear rules for the use of AI 🇪🇺
The #AIAct is much more than a rulebook — it's a launchpad for EU startups and researchers to lead the global AI race.
The best is yet to come! 👍 pic.twitter.com/W9rths31MU
— Thierry Breton (@ThierryBreton) December 8, 2023
Here’s the problem with leading the world in regulation: you can only regulate what is built, and the E.U. doesn’t build anything pertinent to technology.1 It’s easy enough to imagine this tale being told in a few year’s time:
The erstwhile center of civilization, long-since surpassed by the United States, leverages the fundamental nature of technology to regulate the Internet for the entire world. The powers that be, though, seemingly unaware that their power rested on the zero marginal cost nature of serving their citizens, made such extreme demands on U.S. tech companies that they artificially raised the cost of serving their region beyond the expected payoff. While existing services remained in the region due to loyalty to their existing customers, the region received fewer new features and new companies never bothered to enter, raising the question: if a regulation is passed but no entity exists that is covered by the regulation, does the regulation even exist? If only the E.U. could have seen how the world — and its place in it! — had changed.
Or, to use Breton’s description, a launchpad without a rocket is just a burned out piece of concrete.
I wrote a follow-up to this Article in this Daily Update.
French startup Mistral is building compelling large language models; the Nvidia action in particular could be fatal to their future ↩